Import Best Practices
The Anthology Reach data import process (framework) is designed as a scheduled batch process best suited to import incremental transactional data to an Excel or CSV file output. The process works best for data added or changed within 24-48 hours. The import process is not suitable for large volume data migration activities.
The topics in this section provide information to help you evaluate your import process requirements during design of your import, and to optimize your import run time settings to best suit your business needs.
Import Template Design
Designing an efficient import process involves considering various factors. You can optimize your import runs by adjusting settings based on your import template design. When planning and designing your import, keep the following points in mind:
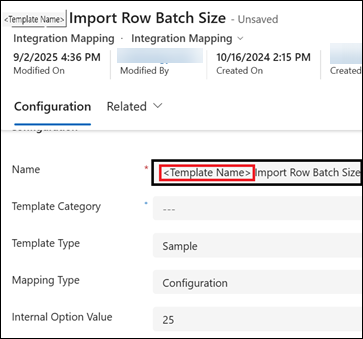
- The Row Batch Size is the number of rows a single azure function instance can handle within the Maximum Azure Function timeout.
-
This value is configured in the <Template Name> Import Row Batch Size integration mapping record in Reach.
-
An optimal value of the Row Batch Size parameter improves file import performance, resulting in faster processing.
The following information help in determining the optimal Row Batch Size:
-
Number of related entity mappings in the template - Row Batch Size is inversely proportional to the number of related entity mappings in the template.
-
When there are more related entities - use a smaller row batch size.
-
When there are fewer related entities - use larger row batch size.
-
-
VendorFileImportQueueTrigger Azure Function Execution Time - The Row Batch Size should be adjusted based on the number of rows processing time within this limit.
-
Always consider approximately 7 to 8 minutes as the safe limit of the Azure function execution time to avoid unexpected failures.
Note: The maximum Azure Function timeout is 10 minutes.
-
-
-
Perform the file import process using the following values for Row Batch Size:
Note: For steps to perform a file import, see Configuring Scheduled File Imports and File Import Overview.-
Set the Row Batch Size as 20 - If the template has around 10–15 related entities.
-
Set the Row Batch Size as 40 - If the template has around 5–10 related entities.
-
-
After the sample import process is completed, analyze the statistics. To do so:
Prerequisite: Obtain the Tracking Id of the most recent flow run for the import process. For steps see, Viewing the Tracking Id for a Flow.-
Run the following query snippet in the Azure App Insights.
 KQL Query Snippet to Determine the Row Batch Size
Copy
KQL Query Snippet to Determine the Row Batch Size
Copyunion traces
| union exceptions
| extend TrackingId = tostring(customDimensions['Trackingid'])
| extend InvocationId = tostring(customDimensions['InvocationId'])
| where TrackingId == "a9eba018-0421-45b5-9604-4fc708c4a17e"
| where message in (
"Entered the queue trigger, OperationName :importrowdatas",
"Exiting the queue trigger, OperationName :importrowdatas"
)
| order by timestamp asc
| project
timestamp,
message = iff(message != '', message, iff(innermostMessage != '', innermostMessage, customDimensions.['prop__{OriginalFormat}'])),
logLevel = customDimensions.['LogLevel'],
severityLevel,
TrackingId,
InvocationId
| summarize
StartTime = minif(timestamp, message startswith "Entered"),
EndTime = maxif(timestamp, message startswith "Exiting")
by InvocationId
| extend DurationSeconds = datetime_diff('second', EndTime, StartTime)
| summarize
AvgDurationSeconds=avg(DurationSeconds),
MinimumDurationSeconds=min(DurationSeconds),
MaximumDurationSeconds=max(DurationSeconds) -
Review the Min, Max, and Avg Azure Function Execution Time in the query result.
-
-
Adjust the Row Batch Size based on the value of the MaximumDurationSeconds in the query result:
-
If it is 7 to 8 minutes - The current value of the Row Batch Size is optimal.
-
If it is 5–6 minutes - Increase Row Batch Size value by 30%.
-
If it is 2–5 minutes - Double the Row Batch Size value.
-
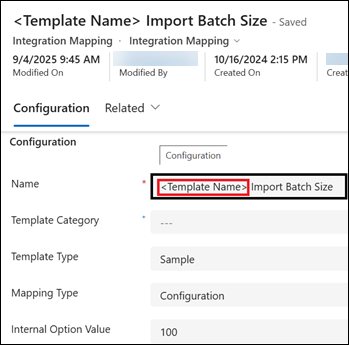
- The Batch Size value defines how many rows from the import file are split into smaller files (split files) for record creation in D365.
-
This value is configured in the <Template Name> Import Batch Size integration mapping record in Reach.
-
An optimal value of the Batch Size parameter improves file import performance, resulting in faster processing. The optimal value depends on the following:
-
Number of related entity mappings in the template - Batch Size is inversely proportional to the number of related entity mappings in the template.
-
More related entities - use a smaller batch size.
-
Fewer related entities - use larger batch size.
-
-
Azure Function Execution Time - Adjust the Batch size to stay within the following limit:
-
Always consider approximately 7 to 8 minutes as the safe limit of the Azure function execution time to avoid unexpected failures.
Note: The maximum Azure Function timeout is 10 minutes.
-
-
Total Rows Content Size (must not exceed 10 MB)
-
Each split file is processed and sent to Power Automate Flow as a response.
-
Power Automate Flow supports a maximum response size of 10 MB.
-
-
-
Perform the file import process using the following values for the Batch Size:
Note: For steps to perform a file import, see Configuring Scheduled File Imports and File Import Overview.-
Set the Batch Size to 100 - If the template has around 10–15 related entities
-
Set the Batch Size to 150 - If the template has around 5–10 related entities
-
-
After the sample import process is completed, analyze the statistics. To do so:
Prerequisite: Obtain the Tracking Id of the most recent flow run for the import process. For steps see, Viewing the Tracking Id for a Flow.-
Run the following query snippet in the Azure App Insights.
KQL Query Snippet to Determine the Batch Size
Copyunion traces
| union exceptions
| extend TrackingId = tostring(customDimensions['Trackingid'])
| extend InvocationId = tostring(customDimensions['InvocationId'])
| where TrackingId == "a9eba018-0421-45b5-9604-4fc708c4a17e"
| where message in (
"Entered the queue trigger, OperationName : parsefile",
"Exiting the queue trigger, OperationName : parsefile"
)
| order by timestamp asc
| project
timestamp,
message = iff(message != '', message, iff(innermostMessage != '', innermostMessage, customDimensions.['prop__{OriginalFormat}'])),
logLevel = customDimensions.['LogLevel'],
severityLevel,
TrackingId,
InvocationId
| summarize
StartTime = minif(timestamp, message startswith "Entered"),
EndTime = maxif(timestamp, message startswith "Exiting")
by InvocationId
| extend DurationSeconds = datetime_diff('second', EndTime, StartTime)
| summarize
AvgDurationSeconds=avg(DurationSeconds),
MinimumDurationSeconds=min(DurationSeconds),
MaximumDurationSeconds=max(DurationSeconds) -
Review the Min, Max, and Avg Azure Function Execution Time in the query result.
-
-
Adjust the Batch Size based on the value of the MaximumDurationSeconds in the query result:
-
≥ 8 minute - The current value of the Batch Size is optimal.
-
5–8 minute - Increase the Batch Size vaue by 50%.
-
2–5 minutes - Double the Batch Size value.
Note: Ensure the 10 MB response size limit is not exceeded.
-
-
Reduce the Batch Size value if:
-
Azure Function fails with timeout.
-
Power Automate Flow fails due to "exceeds the 10 MB response size limit".
-
-
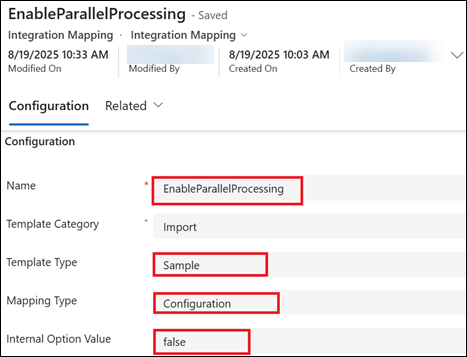
The EnableParallelProcessing value determines whether multiple import file rows are processed in parallel to create records in Dynamics 365.
-
The EnableParallelProcessing integration mapping record needs to be created, and then set to one of the following values.
-
True / Yes / 1 - Indicates parallel processing is enabled.
Important: Set the value to True only if the import file does not contain any duplicate record to avoid creating duplicates in Dynamics 365. All the records in the file should be unique. -
False / No / 0 - Indicates parallel processing is disabled. It is the default value.
-
-
Enabling parallel processing can significantly improve the file import performance and speed.
-
When the EnableParallelProcessing is set to True, the system processes 20 rows in parallel. This value can be adjusted in the Azure Portal by updating the value of the MaxDegreeOfParallelism Azure Function App variable.
Note:
-
The value of the MaxDegreeofParallelism variable is considered for file import only when EnableParallelProcessing is set to True.
-
If you want to update the default value of the MaxDegreeOfParallelism variable, you need to raise a Support ticket with Anthology and provide the following details:
-
The Reach environment variable.
-
Update the following environment variable value in the Import Export Function App:
-
Variable name: MaxDegreeOfParallelism
-
Variable Value: <integer value>
-
-
-
-
Set EnableParallelProcessing to True, and perform the file import process using the following values for the Row Batch Size :
Note: For steps to perform a file import, see Configuring Scheduled File Imports and File Import Overview.-
Set the Row Batch Size to 20 - If the template has around 10–15 related entities
-
Set the Row Batch Size to 40 - If the template has around 5–10 related entities
-
-
After the sample import process is completed, analyze the statistics. To do so:
Prerequisite: Obtain the Tracking Id of the most recent flow run for the import process. For steps see, Viewing the Tracking Id for a Flow.-
Run the following query snippet in the Azure App Insights.
KQL Query Snippet to Determine the MaxDegreeOfParallelism
Copyunion traces
| union exceptions
| extend TrackingId = tostring(customDimensions['Trackingid'])
| extend InvocationId = tostring(customDimensions['InvocationId'])
| where TrackingId == "a9eba018-0421-45b5-9604-4fc708c4a17e"
| where message in (
"Entered the queue trigger, OperationName :importrowdatas",
"Exiting the queue trigger, OperationName :importrowdatas"
)
| order by timestamp asc
| project
timestamp,
message = iff(message != '', message, iff(innermostMessage != '', innermostMessage, customDimensions.['prop__{OriginalFormat}'])),
logLevel = customDimensions.['LogLevel'],
severityLevel,
TrackingId,
InvocationId
| summarize
StartTime = minif(timestamp, message startswith "Entered"),
EndTime = maxif(timestamp, message startswith "Exiting")
by InvocationId
| extend DurationSeconds = datetime_diff('second', EndTime, StartTime)
| summarize
AvgDurationSeconds=avg(DurationSeconds),
MinimumDurationSeconds=min(DurationSeconds),
MaximumDurationSeconds=max(DurationSeconds) -
Review the Min, Max, and Avg Azure Function Execution Time in the query result.
-
-
Adjust the Row Batch Size and MaxDegreeOfParallelism values based on the value of the MaximumDurationSeconds in the query result:
-
7 - 8 minutes - Indicates the current value of the Row Batch Size and MaxDegreeOfParallelism are optimal.
-
5 – 7 minutes - Increase the value of Row Batch Size and MaxDegreeOfParallelism by 30%.
-
2 – 5 minutes - Double the value of Row Batch Size and MaxDegreeOfParallelism.
Important ConsiderationsThe value of MaxDegreeOfParallelism directly influences how much you can increase the Row Batch Size.
-
Increasing MaxDegreeOfParallelism will raise CPU utilization, which can negatively impact the performance of other processes.
-
Always be cautious when adjusting the value of this parameter.
-
Service Protection API Limits (Throttling):
-
Requests per user: Each user is typically allowed up to 6,000 API requests within a five-minute sliding window. Exceeding this limit results in a throttling error.
-
Execution time: The combined execution time of all requests made by a user is limited to 20 minutes (1200 seconds) within the same five-minute sliding window.
-
Concurrent requests: The number of concurrent requests made by a user is also limited, typically to 52 or higher.
-
-
-
Dataset mapping reduce the time required to scan import files for lookup values across related entities, thereby improving the overall performance of the file import process.
-
It is recommended to configure default values for lookup mappings of related entities where values are static and do not change dynamically.
For steps on how to add default values to integration mappings, see Configurations in Integration Mapping Records.
For imports, leverage the external ID column if your template has a unique field. This can bypass Dynamics’ duplicate-checking rules, reduce load and enhance performance.
For example, you can use course id as unique filed in the import file, with this, system will not execute the out-of-the-box Dynamics CRM duplicate detection rules. For more information, see Duplicate Checks for the Import Process section in File Import Overview.
Utilize the delta process, as the Import/Export framework is designed for handling delta records. This framework is not recommended for large-scale migration activities. For information on Delta Process, see Creating Delta Files for Import.
Avoid triggering all flows simultaneously to reduce server load. Use scheduled runs to stagger processes.